Your personal, locally-run LLM. Train it on your own PDFs or Any source and watch it become an expert on your knowledge.
Your personal, locally-run LLM. Train it on your own PDFs or Any source and watch it become an expert on your knowledge. Unlike other models, ShortGPT retains all previously learned information. Every time you add new documents and retrain, it simply expands its understanding – never forgetting what it learned before. Get accurate, consistent results, tailored to your specific needs.
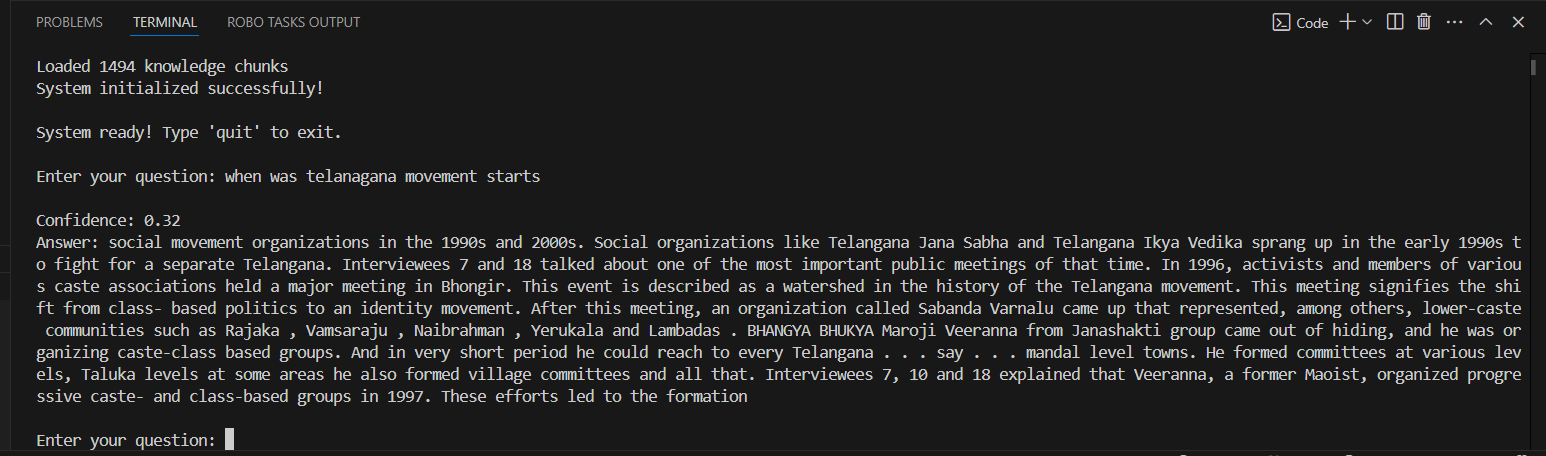
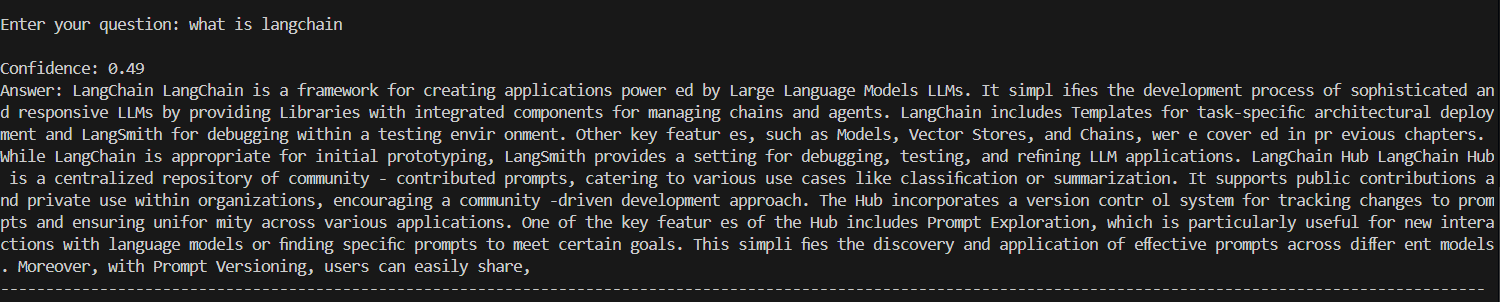
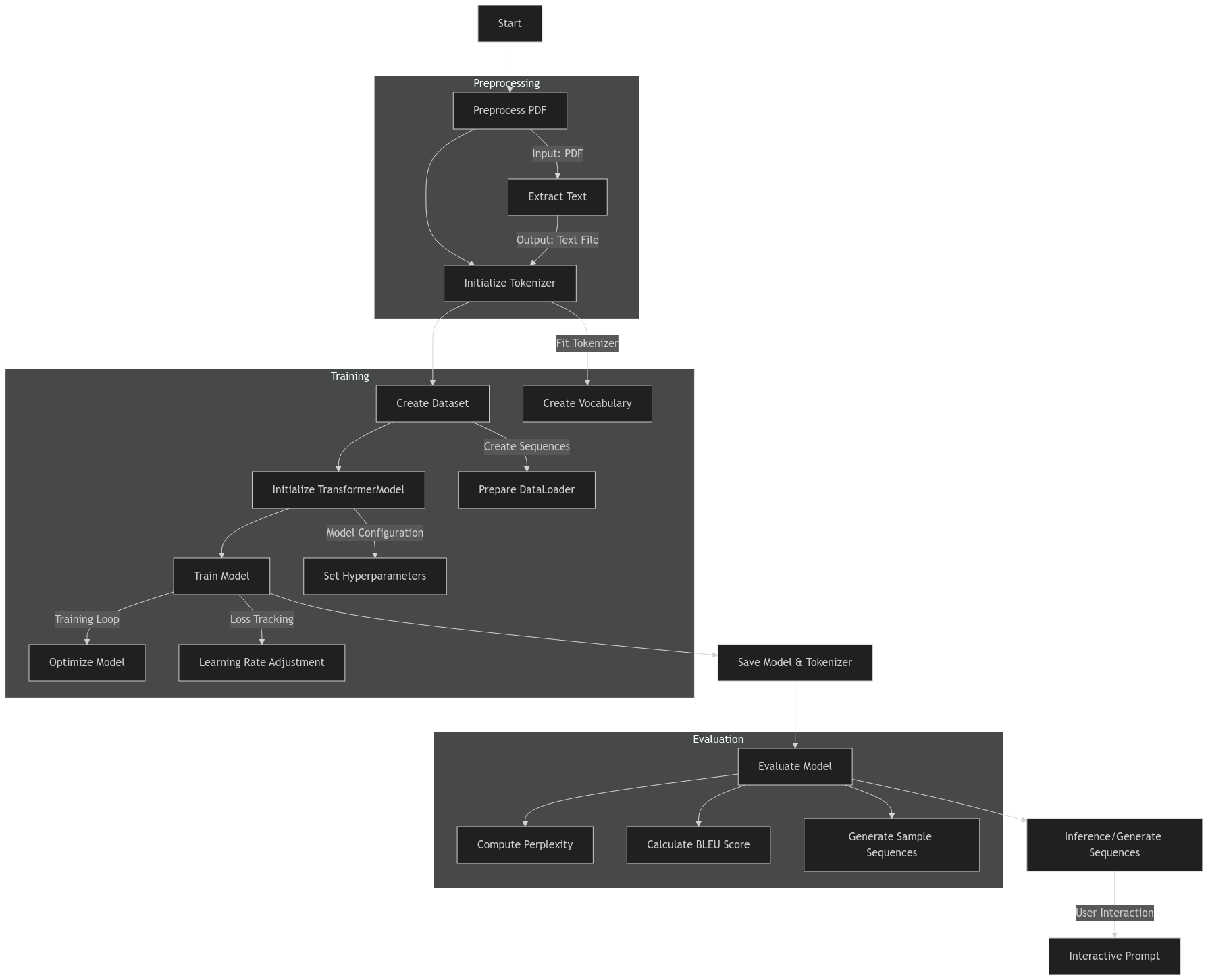
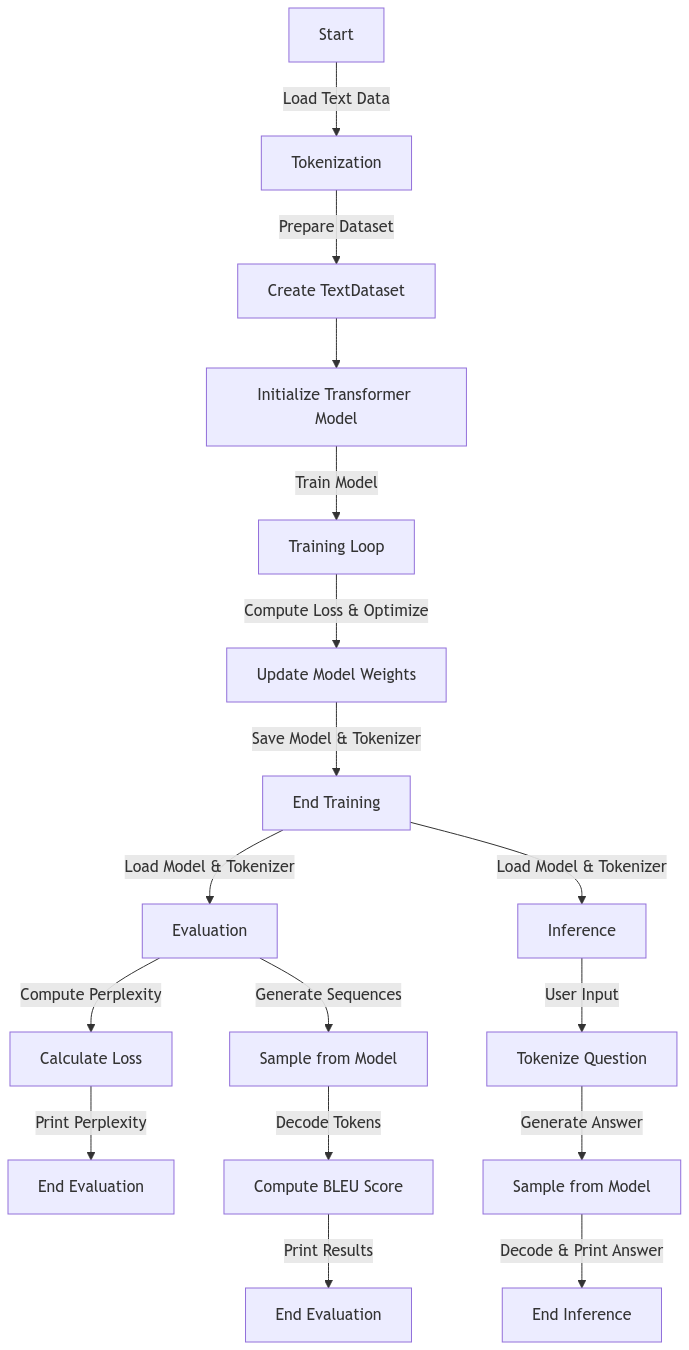
Train the model with your specific knowledge like (pdf,txt) and get responses from model.
Optimized for both GPU and CPU environments, providing flexible deployment options.
Built with custom transformers, attention layers, and positional encoders for optimal performance.
| Algorithm | Description | Benefit |
|---|---|---|
| Transformer | Replaces RNNs with self-attention | Fast parallel processing |
| Multi-Head Self-Attention (8 heads) | Learns multiple relationships in parallel | Improves context understanding |
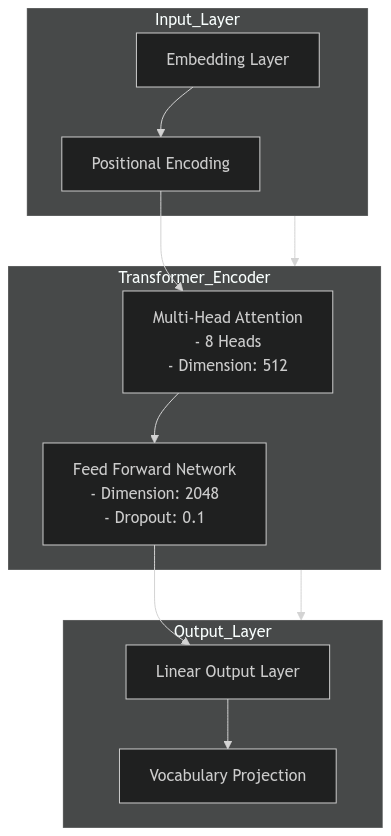
| 512-Dimension Embeddings | Represents tokens with high-dimensional vectors | Captures complex meanings |
| 2048-Dimension Feed-Forward Layer | Expands and compresses attention output | Enhances feature extraction |
| Word-Level Tokenization | Uses full words instead of subwords | Simplifies processing, useful for short texts |
| Frequency-Based Vocabulary Truncation | Keeps only high-frequency words | Reduces memory usage and speeds up inference |
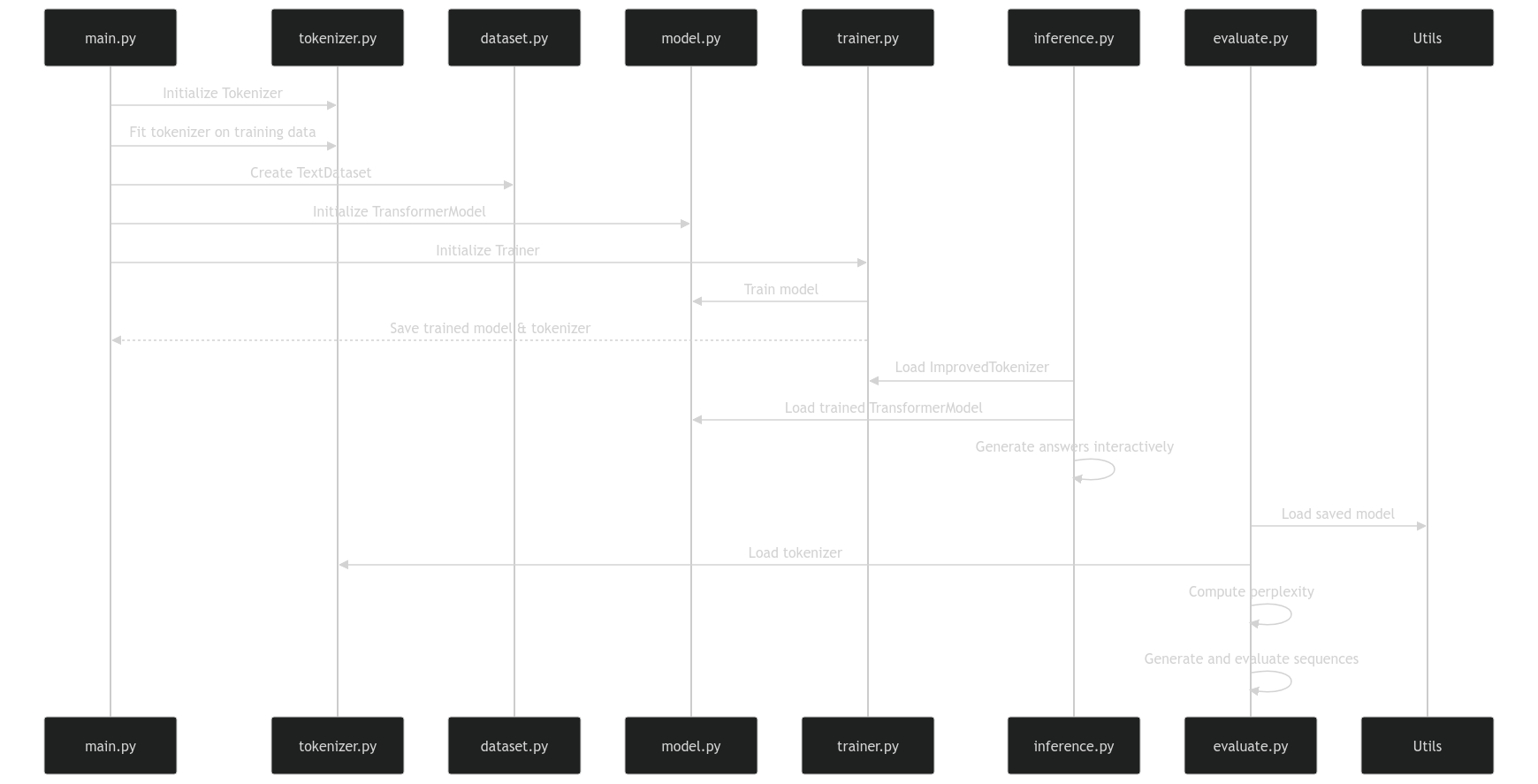

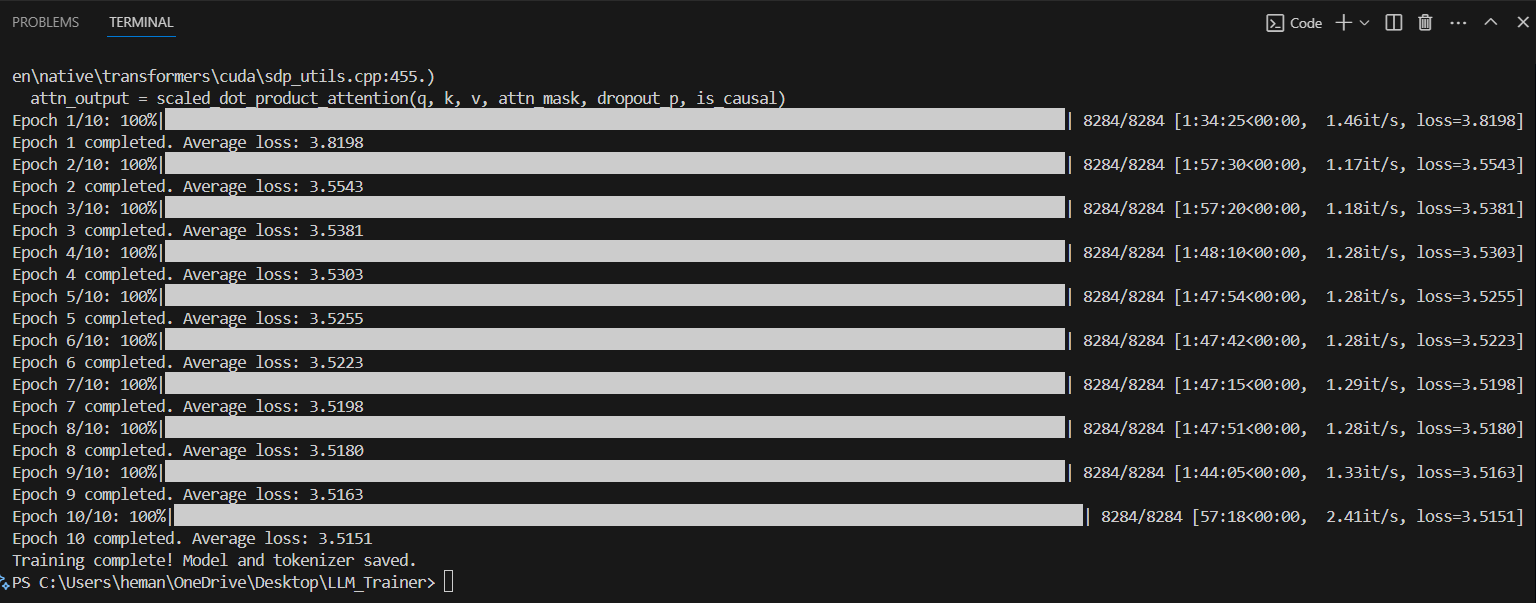
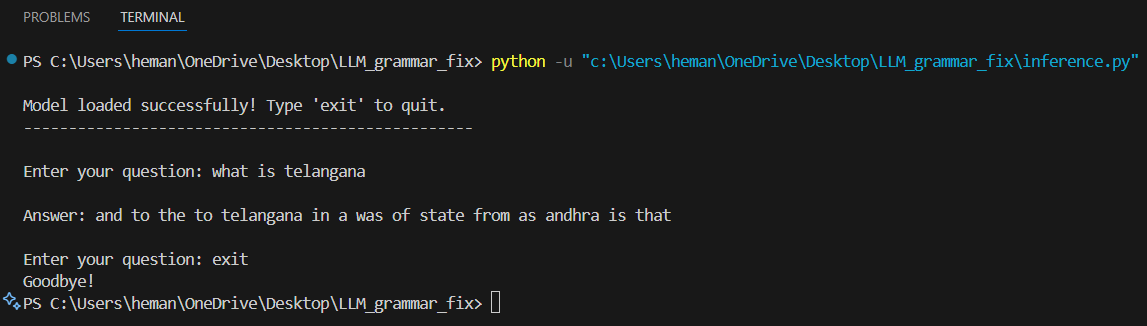
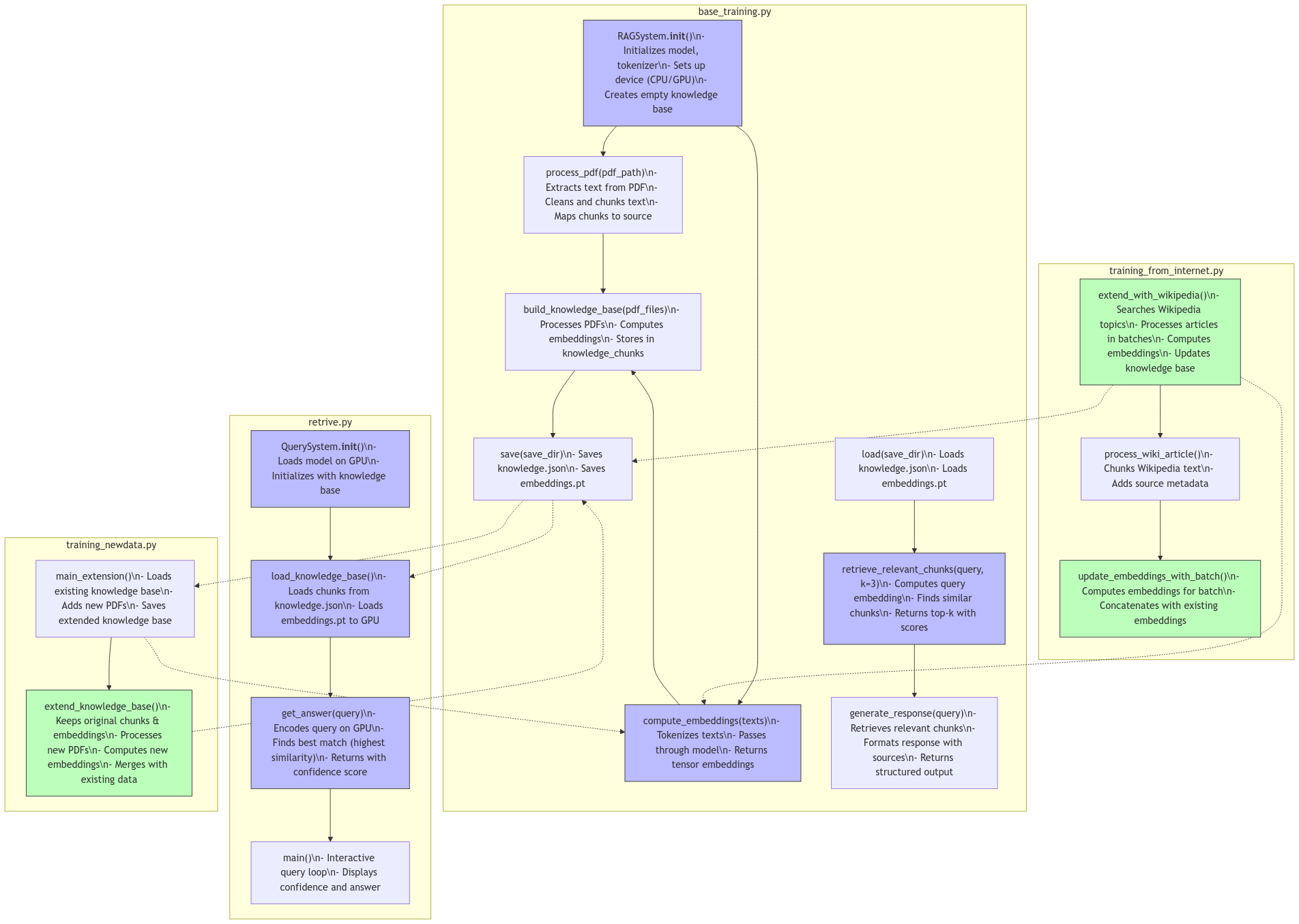
ShortGPT with Retrieval Augmented Generation (RAG) enhances the core model with real-time document retrieval capabilities. This approach allows the model to access and leverage external knowledge during inference.
Seamlessly incorporate PDFs, Wikipedia articles, and other text sources into a unified knowledge base.
Dual-format storage with JSON for metadata and PyTorch tensors for vector embeddings enables fast retrieval.
Memory-efficient handling of large datasets through incremental batch processing and smart caching.
Train the model with your specific knowledge like (pdf,txt) and get responses from model.
Optimized for both GPU and CPU environments, providing flexible deployment options.
Built with custom transformers, attention layers, and positional encoders for optimal performance.
| Component/Algorithm | Description | Benefit |
|---|---|---|
| Transformer | Replaces RNNs with self-attention | Fast parallel processing |
| Multi-Head Self-Attention (8 heads) | Learns multiple relationships in parallel | Improves context understanding |
| 512-Dimension Embeddings | Represents tokens with high-dimensional vectors | Captures complex meanings |
| 2048-Dimension Feed-Forward Layer | Expands and compresses attention output | Enhances feature extraction |
| Word-Level Tokenization | Uses full words instead of subwords | Simplifies processing, useful for short texts |
| Frequency-Based Vocabulary Truncation | Keeps only high-frequency words | Reduces memory usage and speeds up inference |
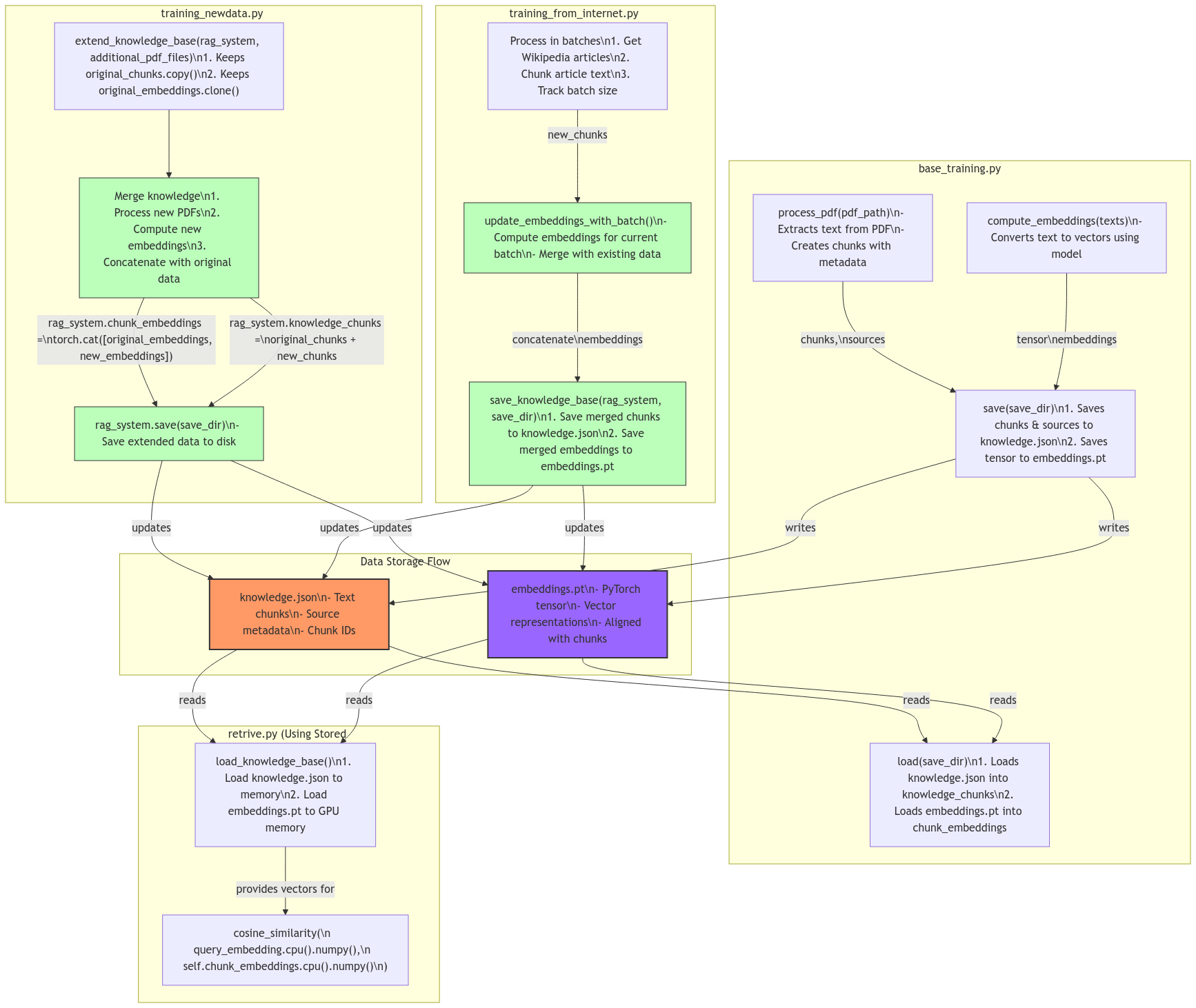
| knowledge.json | Storage for text chunks, source metadata, and chunk IDs | Organizes textual data with context information |
| embeddings.pt | PyTorch tensor with vector representations aligned with chunks | Enables fast similarity search for retrieval |
| process_pdf() | Extracts text from PDF and creates chunks with metadata | Prepares documents for embedding and retrieval |
| compute_embeddings() | Converts text to vectors using embedding model | Creates semantic representations for chunks |
| save() | Saves chunks, sources, and tensor embeddings to disk | Persists knowledge base for future use |
| load() | Loads knowledge.json and embeddings.pt into memory | Prepares knowledge base for querying |
| extend_knowledge_base() | Copies original chunks and clones original embeddings | Preserves existing data while preparing for extension |
| Merge knowledge | Processes new PDFs, computes embeddings, concatenates with original | Integrates new information with existing knowledge |
| Process in batches | Gets Wikipedia articles, chunks text, tracks batch size | Manages memory usage for large corpus processing |
| update_embeddings_with_batch() | Computes embeddings for current batch and merges with existing data | Allows incremental updates to knowledge base |
| load_knowledge_base() | Loads knowledge.json to memory and embeddings.pt to GPU memory | Optimizes retrieval performance with GPU acceleration |
| cosine_similarity() | Compares query embedding with chunk embeddings | Identifies most relevant chunks for response generation |
| torch.cat() | Concatenates original and new embeddings tensors | Efficiently merges vector representations |
| CPU/GPU Memory Management | Strategically moves tensors between CPU and GPU memory | Balances performance and memory constraints |
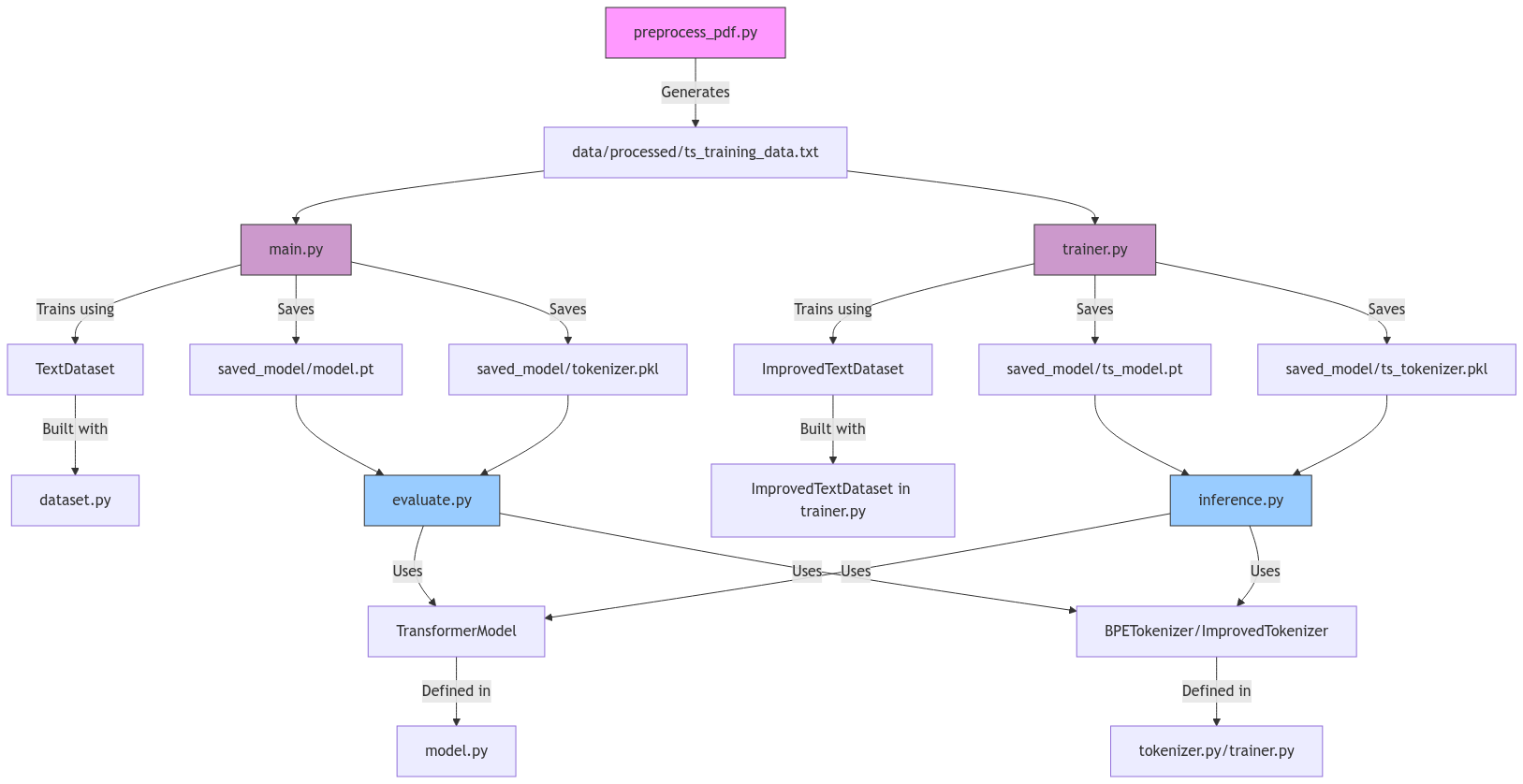
The system uses knowledge.json for storing text chunks with metadata and embeddings.pt for vector representations in PyTorch format.
Documents are extracted, chunked, and associated with metadata through the process_pdf() function for structured knowledge representation.
Text chunks are transformed into 512-dimensional vector embeddings capturing semantic meaning for effective retrieval operations.
The system can incorporate new documents while preserving original data through careful copying and tensor concatenation operations.
Wikipedia articles are processed in manageable batches to enrich the knowledge base while maintaining memory efficiency.
Cosine similarity between query and chunk embeddings leverages GPU processing for fast and accurate information retrieval.
The system employs 8-head self-attention mechanisms to learn multiple relationship patterns in parallel across text data.
A 2048-dimension feed-forward layer expands and compresses attention output for enhanced feature extraction capabilities.
Word-level tokenization simplifies processing for short texts while frequency-based vocabulary truncation optimizes memory usage.